Migrate SQL Server to Aurora PostgreSQL
Data migration is an important process in modern business that involves transferring data from one system or environment to another. As organizations grow and evolve, the need for data migration becomes inevitable. Whether it's moving to a new software platform, modernizing infrastructure, or merging with another company, data migration plays a key role in ensuring a smooth transition and maintaining data integrity.
The main of the prerequisite that lays the foundation for a successful migration is to understand Source and Target systems. By understanding these key aspects, companies can mitigate risks, minimize downtime, and unlock the full potential of their information assets. Today we will dive into a specific case - migrate SQL Server to Aurora Postgre SQL.
Let’s begin from fundamental understanding of our platforms.
What is a SQL Server?
SQL Server is a relational database management system (RDBMS) developed by Microsoft. It provides a reliable and scalable platform for storing, searching, and managing structured data. SQL Server supports various functions, including data storage, data manipulation, transaction management, security, and high availability.
Life with SQL Server
When migrating data from SQL Server, several challenges and common issues can happen. These issues can affect the migration process and require careful consideration and planning.
One of the main challenges is ensuring compatibility between the Source SQL Server database and the Target database system. Different database platforms may have differences in SQL syntax, data types, indexing mechanisms, and stored procedure languages. The migration of complex queries, functions, and stored procedures may require modifications to match the syntax and capabilities of the target database.
Ensuring data accuracy and integrity during the migration process is critical. Data validations such as consistency checks, link integrity checks, and data quality assessments must be performed to identify and resolve any inconsistencies or discrepancies between source and target data. These validation steps are vital to maintaining data integrity in the new environment.
Also, data migration often involves mapping the schema of the source database to the schema of the Target database. Differences in table structures, column naming conventions, constraints, and relationships require careful mapping and conversion during the migration process. Complex data transformations may be required to ensure data integrity and consistency in the Target system.
Migrating large amounts of data from SQL Server can reduce performance and result in extended downtime or business interruption. Optimizing the migration process to minimize the impact on production systems, efficient data extraction and loading methods, and parallel processing can help mitigate performance issues without long downtime. Organizations need to plan for an appropriate maintenance window, implement backup and recovery strategies, and have contingency plans in place for continuity and minimizing the impact on end users.
Another concern when migrating from SQL Server is data security. Ensuring safety in transit and at rest is of paramount importance. Organizations should implement appropriate security measures such as encryption and access control to protect sensitive data during the migration process.
Addressing these challenges and issues requires careful planning, extensive testing, and the involvement of skilled database administrators and migration specialists. It is crucial to carefully analyze the Source SQL Server database, identify potential issues, and develop an appropriate migration strategy to mitigate risks and ensure a smooth and successful data migration process.
What is Amazon Aurora?
Amazon Aurora is a relational database that aims to provide rich and organized data in the form of tables. This allowed users to speed up work and manage the data stored in the database.
It is compatible with all known versions of MySQL and PostgreSQL, which is crucial for its widespread use. Lets look at some awesome features of Amazon Aurora.
According to reports and various tests conducted, it was concluded that Amazon Aurora was able to deliver five times faster and more efficient results to the user on the same provided hardware. It was also noted that Amazon Aurora made full use of the system's components and functions and used them to achieve faster results. Transaction processing services and methods such as quorums allow users to increase productivity and efficiency.
Amazon guarantees the security of your data, and to do so, it uses Amazon RDS, which monitors the health of your database and makes sure to keep a backup copy on site. To protect your data cache, it isolates the database buffer cache, so it is not affected by a database restart and the user can resume the process.
In addition, in the event of a database failure, Amazon RDS will look for Amazon Aurora Replicas and ensure that backups are uploaded to the Amazon Aurora database. Users can create up to 15 Amazon Aurora replicas to cover multiple failure scenarios.
Security and data protection remains one of the best features of Amazon Aurora; it comes with advanced security protocols that ensure that your system becomes impenetrable. Amazon Aurora ensures that your data is stored in a virtual network, making it accessible only to a limited number of users. The firewall and network access can be changed, which are necessary precautions for a secure database. In addition, it transmits data in 256-bit encryption, making it exceptionally secure. This allows users to view data logs and search for various operations performed on the database.
The advantage of using Amazon Aurora is its accessibility, which makes it easy to navigate the various features it provides. It also comes with simple monitoring features that allow you to view different views of the database and ensure that all operations are logged.
Additionally, it uses automatic update features that ensure that your system stays up to date with the latest patches released; Amazon Aurora makes it easy to manage and work with the database. Amazon Aurora also provides a fast clone feature that allows users to clone terabytes of data in a few minutes, which saves a lot of time.
Amazon Aurora Architecture Overview
Amazon Aurora's architecture focuses on component reuse, making it more efficient and faster. Amazon Aurora reuses core operational systems such as recovery, transactions, and query execution, which saves memory and makes the system efficient. This method and architecture saves both memory and time, resulting in improved and efficient performance. Some new enhancements have made Amazon Aurora even better and they are listed below.
AWS Aurora PostgreSQL is compatible with PostgreSQL 9.6 and PostgreSQL 10. It is extremely easy to set up PostgreSQL with Aurora, as it can increase the throughput and efficiency of operations performed on the database. A PostgreSQL-compatible Aurora instance can be launched from the Amazon RDS console and then use PostgreSQL as the edition and Amazon Aurora as the engine.
How to Migrate Data from SQL Server to AWS Aurora PostgreSQL using Repstance
Repstance Tool
Repstance is an innovative and extremely versatile, Enterprise Class data Facilitation tool. By “Facilitation” we mean that, by using Repstance you are able to deploy, distribute, change and use your most valuable asset — your Data — in ways that are either, not available or are cost prohibitive when compared to other solutions, as well as performing the more basic Migration and ongoing Replication functions, whether that be on your own premises or “In the Cloud”.
Benefits of Repstance
Repstance is able to reload all the required data itself (Initial Load) and automatically include the required tables in the replication process, so only after all the tables are transfused, does Repstance then start processing all data changes in the tables and only from the moment at which the tables were finished within the “Initial Loading” phase.
Another approach is also possible — data is migrated using other tools that can migrate a consistent copy of data, and Repstance is used to replicate changes from the moment at which a consistent data snapshot was taken (the RESET Apply Process function).
Let’s look at this process based on the following example of a configuration for migrating data from SQL Server to AWS Aurora PostgreSQL.
Repstance configuration
Let’s launch Repstance instance from AWS Marketplace. After a few simple configuration steps, you’ll see the user interface.
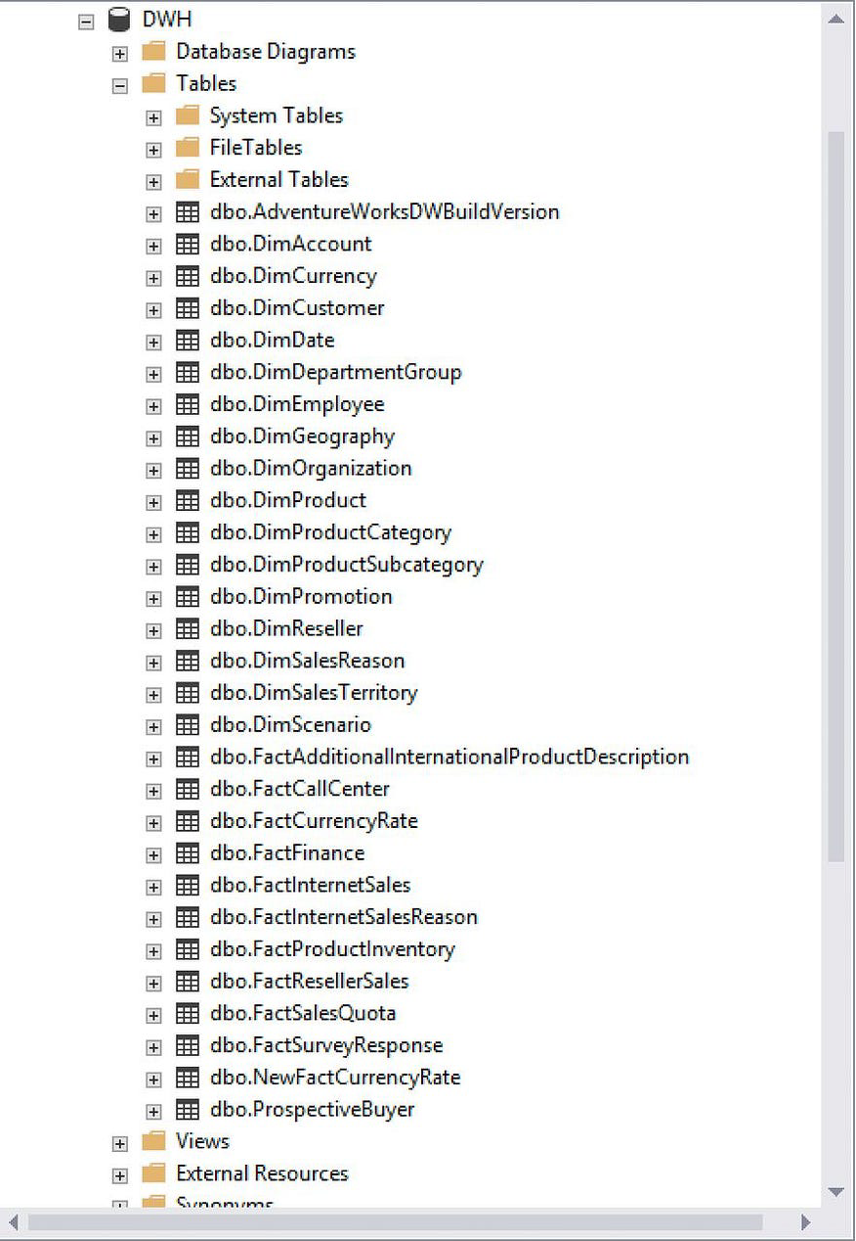
Now we need to create a data structure on Target database, similar to the Source. Here is the Source structure:
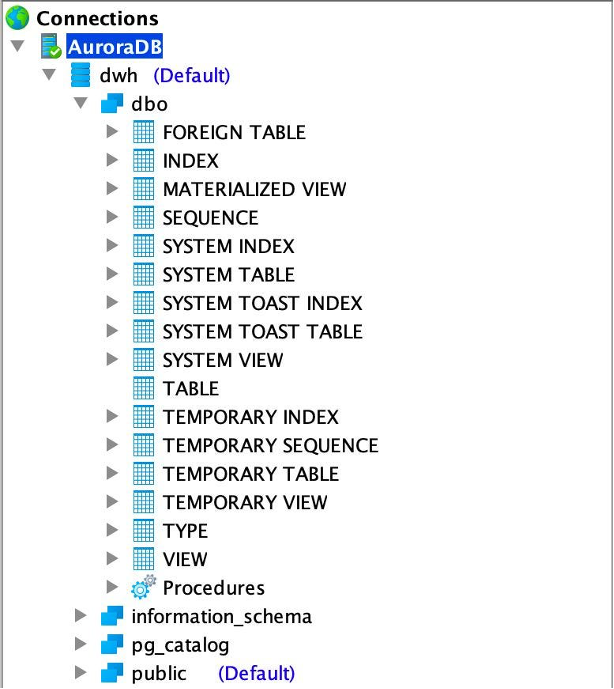
Here is the Target database:
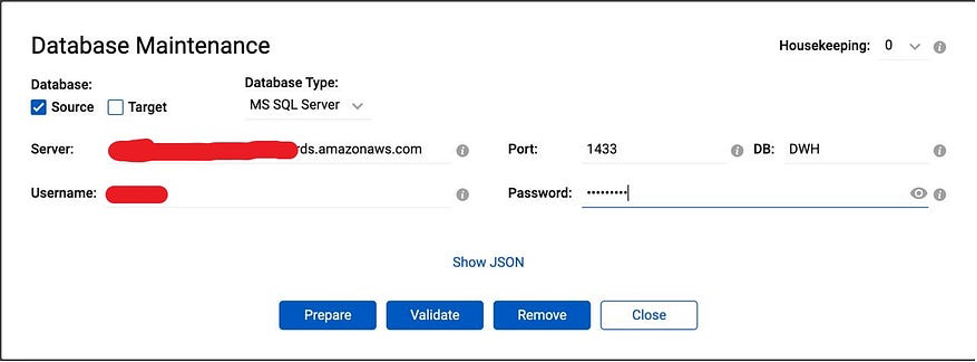
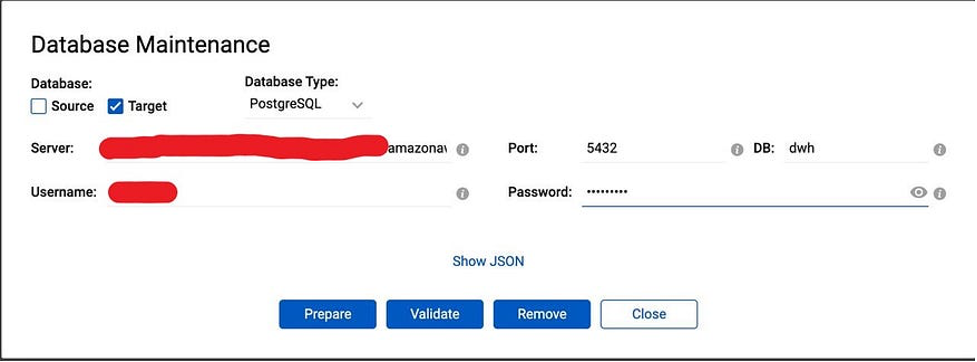
Now we need to prepare our databases for data migration and replication. In the Repstance Dashboard click “Database configuration” and provide the details. For Source database:
And for Target database:
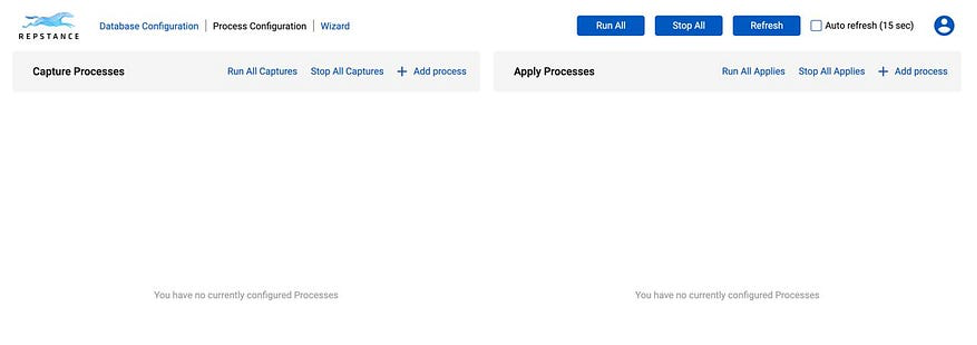
Now we are going to configure Capture and Apply Processes. The Capture Process is the means by which the data to be transferred is extracted from the Source Database. It puts this information into locally stored Trail Files, which the Apply Processes will use. The data from a single Capture Process can therefore be used by many Apply Processes and, as a result, this data can therefore be propagated into multiple Target Databases.
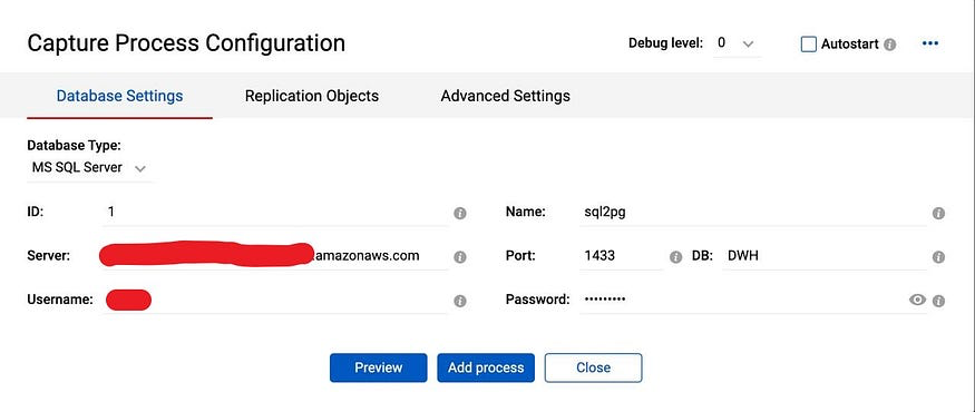
For this, we need to add a new process. Click on “+ Add Process” on the “Capture Process” tab and provide the Capture connectivity details along with process ID and process name:
We are able to select objects that we will migrate. Go to Replication Objects and create migration/replication rules:
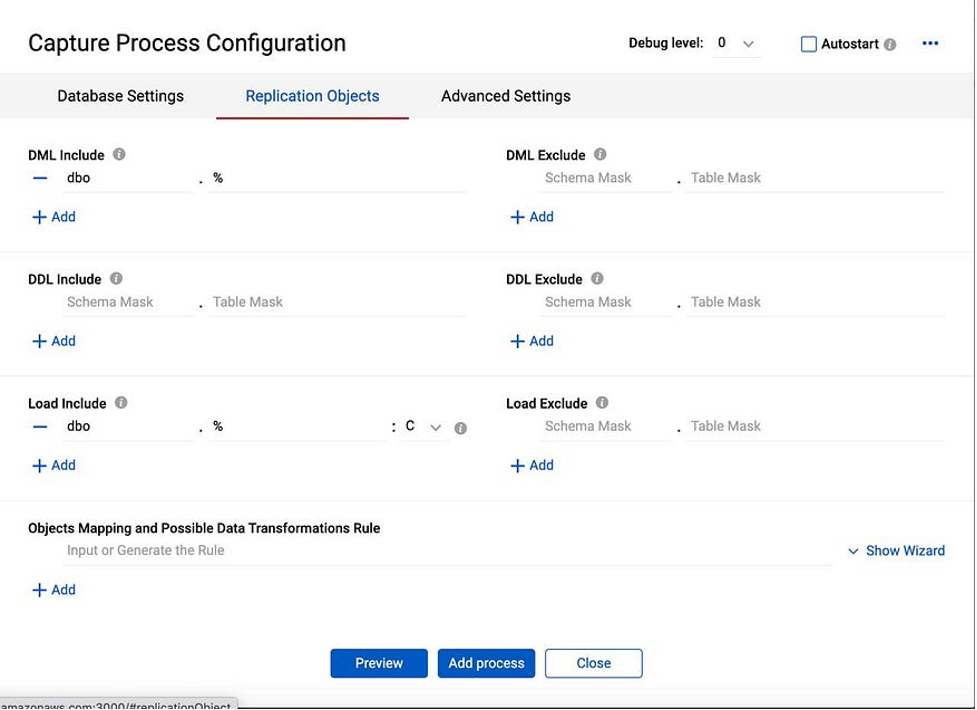
In “DML Include” section we specify group of the tables for the DML replication. Schema Mask is “dbo” and Table Mask is “%”. The “%” symbol may be used in order to match any number of characters, so in this case it means that all the objects under the “dbo” schema will be included in the DML replication.
In the “Load Include” section we are providing the same % symbol, meaning that all the objects will be reloaded before the replication begins.
Additionally, in the “Load include” section we select “C” as the reloading method, which means that the table will be created in the Target database, if it doesn’t exist.
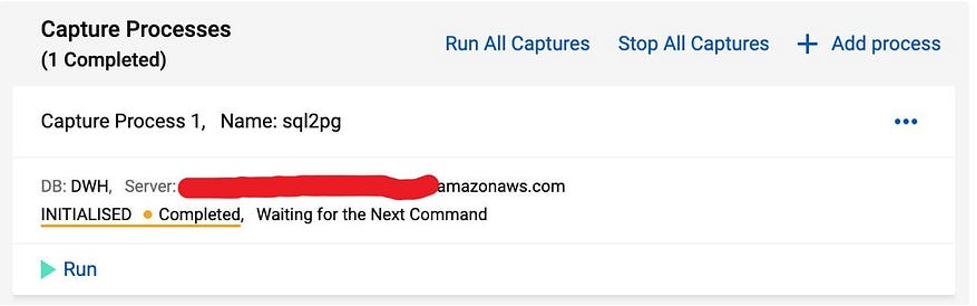
Now the Capture Process is configured and we run it:
But, to populate our Target database, we have to configure Apply Process — Click “+ Add process” on the “Apply” tab:
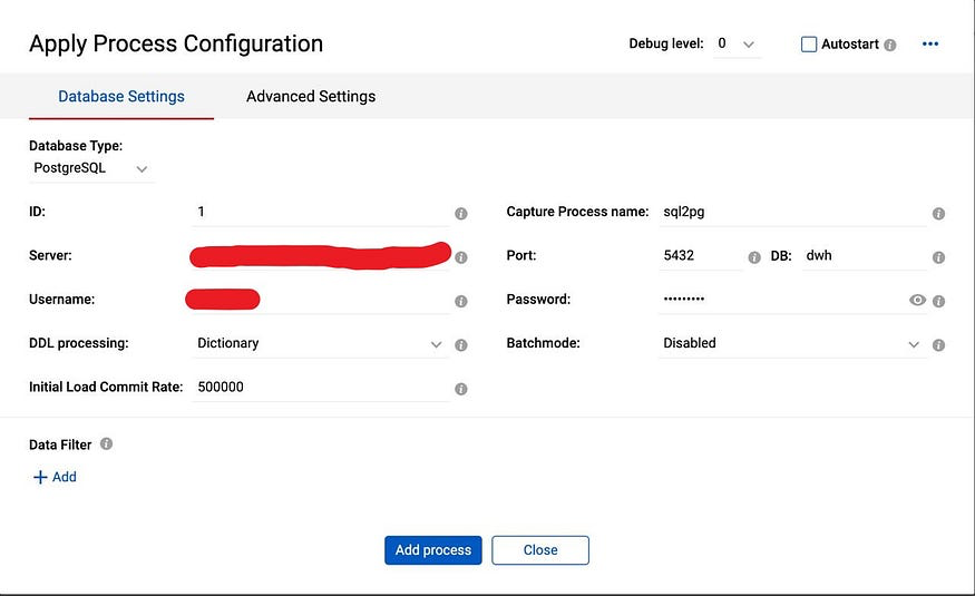
We need to provide Apply ID, Name of the Capture Process, which extracts data and connectivity details. Also, we set “Initial Load Commit Rate” to 500000, which means that loading data (INITIAL LOAD) Repstance will commit the transaction every 500k records.
Once, all the configuration steps are completed, we able to run our migration process and enjoy how extremely fast it is:
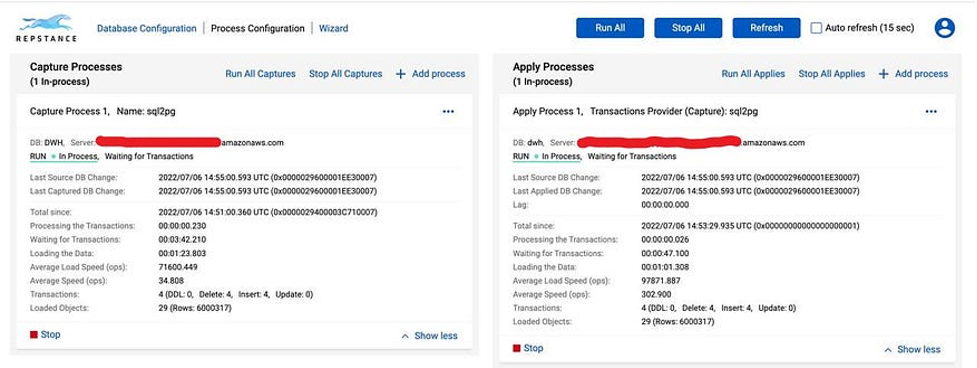
To migrate around 6 million records from SQL Server into AWS Aurora database it took Repstance less than 3 minutes. If we look at the Aurora database we can see that all the tables have been created and data is inserted, so the “Initial Load” phase of the migration is done.
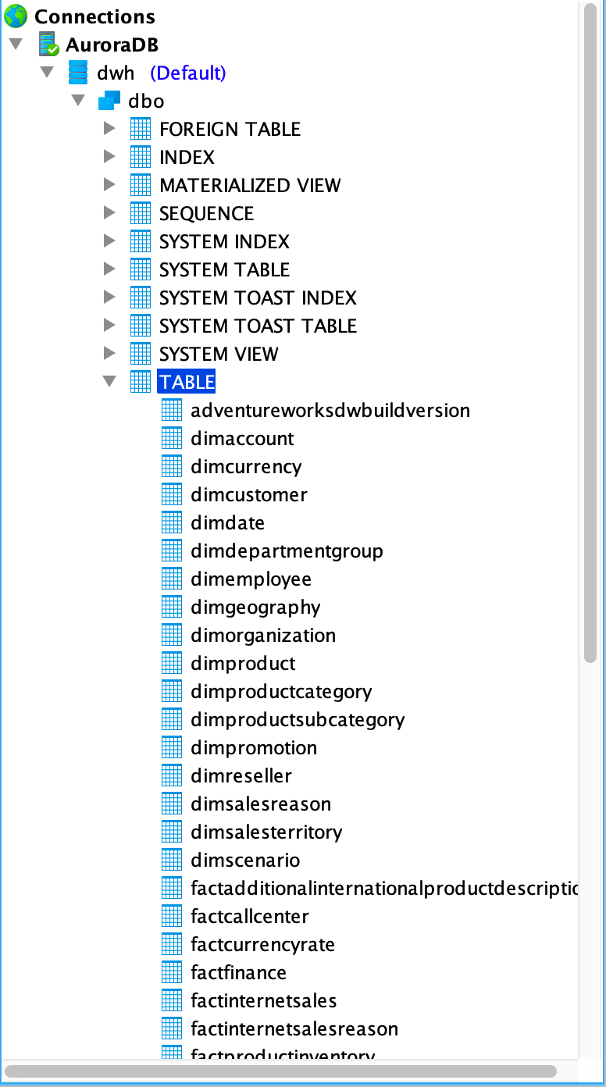
Bear in mind that if some data was modified during or after the migration, Repstance will take care of it and apply all these changes, so the Target database will always be consistent and in “Sync” with the Source database. This is the last step and after it SQL Server to Aurora migration is completed. The database are in sync and any changes occur in the Source database will be immediately replicated into the Target database.
Conclusion
We have described the case of migration and replication data from SQL Server to Aurora PostgeSQL. As you can see, even complicate data migration can be accessible if you choose right tool.
Read also:
Oracle to Snowflake with Repstance
SQL Server to Snowflake data replication