Oracle to Snowflake : Oracle to snowflake migration best practices
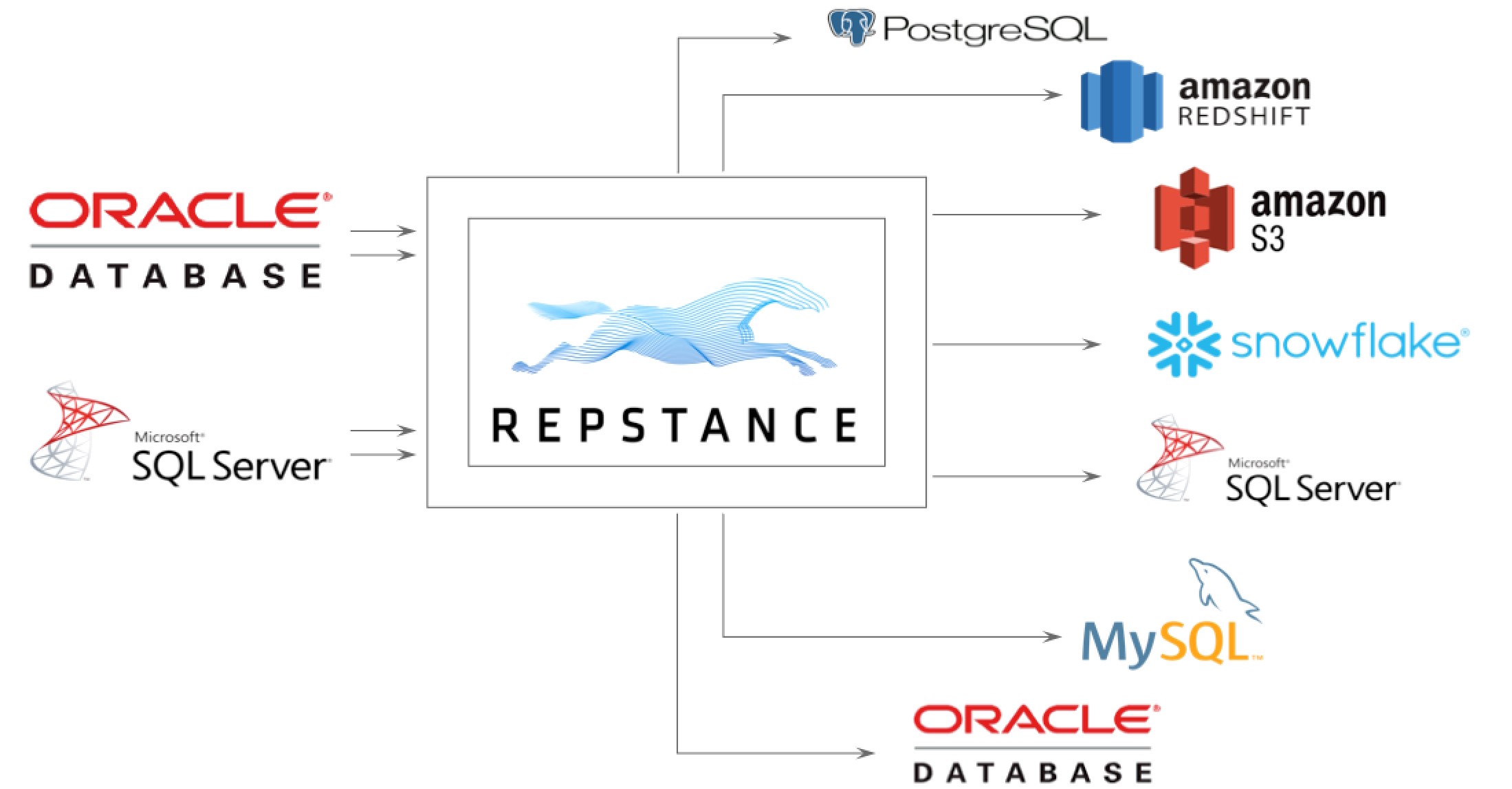
Repstance is a fully managed real-time data propagation tool, which is used to keep data highly available across various databases and enable real-time data processing and analysis.
Repstance supports most of the commonly used databases:
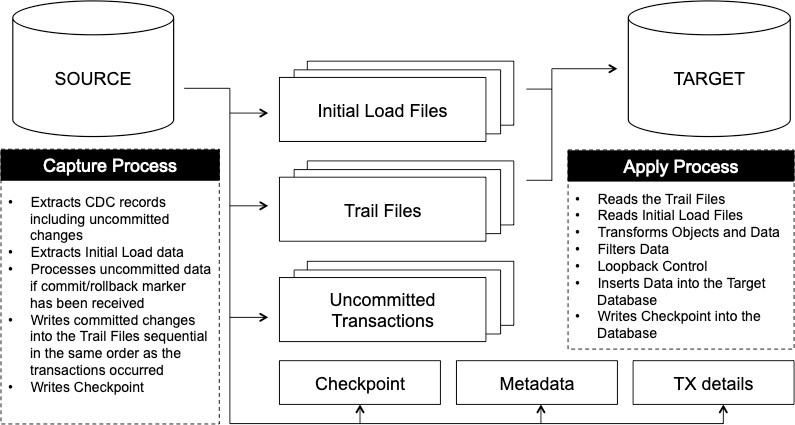
Repstance Architecture Overview
To replicate data Repstance uses Capture and Apply Processes. The Capture Process extracts data from the Source Database and puts it into locally stored Trail Files in the same sequential order as the transactions occurred in the database. The Trail Files are consumed by Apply Process to insert the captured data into the Target Database. The Apply Process can also filter and modify data or/and data definition if the appropriate transformation and filtering rules are configured:
Configure Repstance for Oracle
Before starting the configuration ensure that Oracle database runs in Archive Log mode and the required level of supplemental logging is enabled.
Repstance needs to install minimal set of objects into both Source and Target Databases, which can be done either by running “prepare database” repcli command or through the “Database Configuration” Web UI form.
Select Capturing Method
Capture Process can extract Oracle database changes either using Oracle’s LogMiner functionality or by getting them directly from Redo Logs (Direct Log Mining). It’s important to define preferable capturing method before starting database and process configuration.
LogMiner
LogMiner is a built-in Oracle method that allows you to analyze and extract data changes from the Redo Log files. Oracle uses server-side database process to parse the log files and provide the results using database system views.
Repstance utilizes LogMiner’s functionality to extract data and structural changes for the objects that are included into replication. In this mode Repstance acts as a database client taking data changes parsed by Oracle.
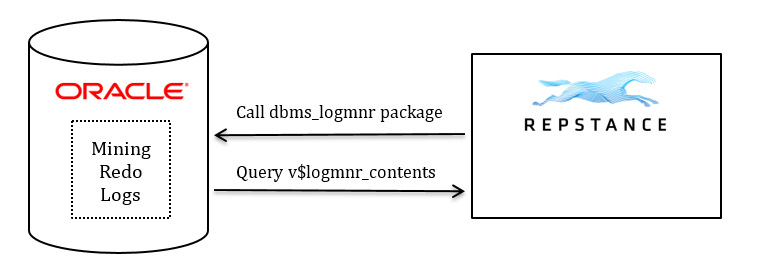
This method is recommended to use in the following cases:
- Small number of changes (less than 5000 DML operations per second) should be replicated
- Possible CPU extra load (up to 15% at peak) is acceptable for the Source Database
- Size of the changes to be extracted is less than 5% of the Redo Log size
- The replication of the LOB objects sized more than 4000 bytes is not required
- Any limitations of Direct Log Mode usage are present
- Access to Redo/Archived Logs is not possible to configure
The LogMiner is the default database capturing method, which is easy to set up and support and requires less database diving.
Direct Log Mode
An alternative to using the LogMiner method is the “Direct Log” mining method. In this mode Repstance extracts data changes directly from Redo or Archived Logs. Since the Redo Log processing takes place out of the Oracle database this method tends to have a lower performance impact on the Source Database compared to LogMiner.
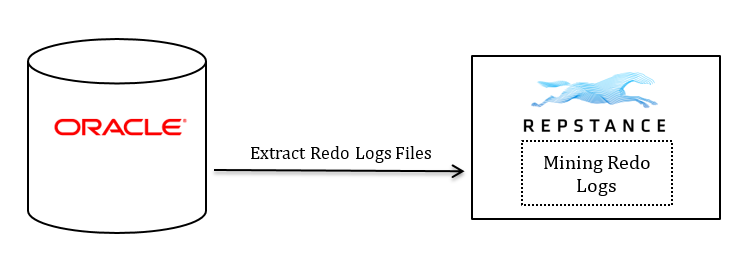
Direct Log Mining method best fits for most databases and is used to meet the following replications requirements:
- High replication speed
- Minimal impact on the Source Database
- Fully supports LOB objects replication
- Replication of Clustered Tables is not required
- Replication of Partitioned Index-Organized Tables is not required
Repstance takes Redo and Archived Logs though the database connection, which depending on the Log’s location can be either to the Database or to the ASM Instance. Alternatively, Repstance can process Archived/Redo logs as local files copied into Repstance Server by any external processes.
Redo on the File System
Repstance receives Redo/Archived Logs using standard database connection by reading them as ORACLE DIRECTORY’s objects.
Repstance requires the “ONLINELOG_DIR” and “ARCHIVELOG_DIR” directories to be created and read access to these directories to be given to the Repstance’s database user. The directories are created by Repstance automatically by providing “createlogdirs=1” parameter while running “prepare” command for the Source Database.
The Capture Process’s “directlogmode” parameter has to be set to “1”.
Redo on ASM
In order to retrieve the Redo/Archived logs stored on the ASM Repstance uses separate database connection to the ASM instance, which needs to be provided as part of Capture Process configuration. The following parameters of the Capture Process are used to specify ASM connection settings:
- asmuser – ASM user name.
- asmpassword – ASM user password.
- asmservicename – Name of the TNS alias contains the connection details to the ASM Instance
The Capture Process’s “directlogmode” parameter has to be set to “2”.
Redo on Repstance local file system
Repstance can read and process Redo/Archived Logs as files assuming that they are available on the Repstance’s sever file system. This mode is enabled by setting the “directlogmode” parameter to “1” and configuring the “locallogdir” parameter.
The Log files should be delivered into this folder by any external process and once Log becomes available Repstance will start processing it immediately. This folder must be created on the Repstance Server’s file system and the “locallogdir” parameter must be set to specify the full folder path. The name of Log files must be the same as they are in the Source Database.
Replication Objects Configurations
Repstance supports both DML and DDL replications. The tables for DML and DDL operations are specified by the different parameters.
DML Replication
DML replication is specified by two Capture Process parameters, they are:
- dmlinclude – list of the tables to be included into the DML replication
- dmlexclude – list of the tables to be excluded from the DML replication
The table will only be replicated in the case that the name matches the “include” criteria and does not match the “exclude” criteria.
The table is specified in “schema_mask.table_mask” format. In order to specify the list of the tables, each table must be separated by comma. The “%” symbol may be used in order to match any number of characters.
DDL Replication
DDL replication is limited and supports only the following operations:
- Create/Drop/Alter Primary Key
- Create/Drop/Alter Unique Index
- Create/Drop Table
- Rename Table
- Truncate Table
- Add/Drop/Alter Table’s Columns
- Add/Drop/Alter Table’s Partition
Same as DML, the DDL tables are specified by pair of include/exclude parameters:
- ddlinclude – list of the tables to be included into the DDL replication – list of the tables to be included into the DDL replication
- ddlexclude – list of the tables to be excluded from the DDL replication
These parameters are also provided in “schema_mask.table_mask” format and support “%” symbol as wildcard.
If table has been created and name of the table matches DDLInclude criteria, the “create statement” will be captured and the table will be included into the replication automatically.
Initial Data Migration
Repstance supports full data migration (Initial Loading Process) for the tables that are included into replication. The Initial Load and Replication Processes are synchronized, meaning that if table is included into Initial Load the Capture Process will collect data changes starting from the SCN/timestamp the data was extracted at.
There are two parameters that are used to configure Initial Load:
- loadinclude – list of the tables to be included into the Initial Load
- loadexclude – list of the tables to be excluded from the Initial Load
The format is “schema_mask.table_mask:[loadOption]”. The “%” symbol (wildcard) is also supported.
loadOption is used to instruct Apply Process on how to migrate data from Oracle to Snowflake:
- A – Load data without running any cleanup and any DDL statements. This is DEFAULT value
- T – Cleanup Target table before data loading by running “truncate table” statement
- D – Cleanup Target table before data loading by running “delete” statement
- C – Create table if it does not exist and load the data
- R – Recreate table if it already exists and load the data
Rename Schema, Table and Columns
To replicate data Repstance generates SQL statements that are based on the Source Database objects’ definitions, which means that if a table is changed in the Source Database, then in the Target Database Repstance will apply these changes to the table having the same name and the same columns.
In cases when object’s definitions differ in the Source and Target databases, the replication process may fail. This behavior can be changed by using Transformation Rules, which are used to:
- Rename schema/table name
- Rename any columns
- Change columns’ attributes
- Exclude/Include columns
- Use SQL function to transform or generate data
The Transformation Rules are applied to the DML replication and depending on configuration, to the DDL replication and Initial Load. The transformations are configured using “Capture Process Configuration” Web UI form or by utilizing “map” parameters of repcli tool.
Configure Repstance for Snowflake
Captured data is used by Apply Process to construct and execute SQL statements that are to apply these changes to the Target Database’s objects. Apply Process requires to configure Target Database connection and setup the “capturename” parameter, which is used to identify the Capture Process providing the data. The Apply Process allows you to configure various data filters and data transformations, which are used to implement complex data processing scenarios.
Initial Data Load for Snowflake
Apply Process performs initial data migration from Oracle to Snowflake and depending on the loading method it creates or cleans up target tables. Apply Process loads the data considering the transformation and mapping rules, thus the same data processing logic is used for the data migration and replication.
By default the data is delivered as compressed files into “Snowflake stage” for further loading into target tables. Apply Process also supports data delivery through the bulk insert into temporary tables, which may be considered in cases when using “Snowflake stage” is unpreferable. This mode is enabled by setting the “stageload” parameter to 0.
Apply Process Transformation Rules
Likewise the Capture Process, the Apply Process supports data and objects transformation. The “map” parameters are used to configure the Transformation Rules.
The Apply side transformations are recommended to use in the case when several Apply Processes are configured to consume data from the same Capture Process and each Apply Process requires a bespoke data processing logic implementation.
The Transformation Rules are applied to the DML replication and Initial Load, and depending on configuration to the DDL replication.
DDL Processing
Repstance offers various options to process DDL transactions. Depending on configuration Apply Process either repeats original DDL statement or constructs the new one based on the objects’ structural changes. The “ddlprocessing” parameter is used to specify DDL processing behavior. It accepts the following values:
- native – this is to repeat original DDL statement. This setting is recommended to use only if Target and Source databases are the same type, otherwise the statement may fail, as the Source DDL statement may not be compatible with the Target database
- dictionary –this is to enable Apply Process to construct DDL statement considering Target Database syntax
- map – this setting is similar to dictionary, except the Transformation Rules will be applied to the “constructed” DDL statement
Configure Oracle to Snowflake Replication and oracle to snowflake migration challenges
As an example we will show how to configure Repstance to replicate data from Oracle to Snowflake. We will setup Oracle to Snowflake migration for all the tables of the HR schema. The transformation rule will be involved to rename schema to ORA_HR, by meaning that Apply Process will reformat all the statements to use the ORA_HR schema instead of HR.
The “Direct Log " capturing method will be configured to extract changes from the Archived/Redo Logs assuming that they are located on local disk of the database server.
The configuration steps are provided below:
- Login into Snowflake and execute the following SQL statement to create ORA_HR schema:
create schema if not exists ORA_HR;
|
- Login in the AWS console and use the following link to setup Repstance Instance https://aws.amazon.com/marketplace/pp/prodview-yze2n2e5znnd6. Ensure that network rules are configured to allow traffic from this instance to both Oracle and Snowflake databases.
- Once the Repstance Instance is available, use SSH protocol to connect to the Repstance Server and invoke the repcli command line tool.
- Run the following repcli command to prepare Oracle database for the replication. The “createdirs=1” option is required to use the “Direct Log Mining” capturing method:
prepare database=source dbtype=oracle connectiontype=ezconnect server=db_host port=1521 servicename=ora_service user=ora_user password=ora_password createlogdirs=1
|
- Prepare the Snowflake database by running the following repcli command:
prepare database=target dbtype=snowflake account=db_account region=eu-west-2.aws warehouse=wh_name user=sf_user password=sf_password dbname=sf_database
|
- Run the following repcli command to create “ora2sf” Capture Process:
prepare process=capture id=1 dbtype=oracle connectiontype=ezconnect server=db_host port=1521 servicename= ora_service user= ora_user password= ora_password name=ora2sf directlogmode=1 dmlinclude=hr.% ddlinclude=hr.% loadinclude=hr.%:C map=1,rule=(hr.%.%:ora_hr.%.%) autostart=1
|
The “directlogmode=1” parameter specifies that “Direct Log Mode” capturing method to be used.
The “dmlinclude=hr.%” and “ddlinclude=hr.%” parameters enable DML and DDL replication for all tables in the HR schema.
The “loadinclude=hr.%:C” parameter is used to load data from Oracle to Snowflake and indicates that all tables in the HR schema to be migrated, while “C” option instructs the Apply Process to create these tables in Snowflake before the loading.
The “map=1,rule=(HR.%:ORA_HR.%)” clause specifies the Transformation Rule to rename schema HR to ORA_HR.
The “autostart=1” parameter determines that the Capture Process must be started after service restart.
- Run the repcli command to create the Apply Process that will replicate data provided by the “ora2sf” Capture Process into the Snowflake database:
prepare process=apply id=1 dbtype=snowflake account=db_account region=eu-west-2.aws warehouse=wh_name user=sf_user password=sf_password dbname=sf_database capturename=ora2df ddlprocessing=map autostart=1
|
The “ddlprocessing” is set to “map” in order to construct DDL statement using Snowflake’s syntax and to rename the HR schema to ORA_HR following the “schema renaming” Transformation Rule.
- Execute “run” command in repcli to start both Apply and Capture Processes.
After this step the configuration is completed. You can use repcli “status” and “report” commands to get detailed information about replication Processes, including statistics on the number and types of the operations, number of transactions, capture and apply speeds, replication lag, etc.
You can follow similar steps to setup replication for most "migrate oracle cdc snowflake" cases. Some configurations like Oracle Exadata to Snowflake replication may require ASM connection to be additionally specified.
Conclusion
In this paper we described various configuration options for Oracle data integrator Snowflake and demonstrated how easy it is to setup full data migration and ongoing replication with Repstance.
Read also: