ABOUT REPSTANCE
Repstance is a fully managed real-time data propagation tool, which is used to keep data highly available across various databases and enable real-time data processing and analysis. Repstance is currently listed on the AWS and Azure platforms and can also be deployed out off the cloud infrastructure.
Repstance supports Oracle 10G - 19C and any version of SQL Server that permits the use of CDC (Change Data Capture) as Source Databases and Oracle 10G - 19C, SQL Server, MySQL, PostgreSQL, Amazon Aurora, Amazon Redshift, Snowflake and S3 as Target Systems:
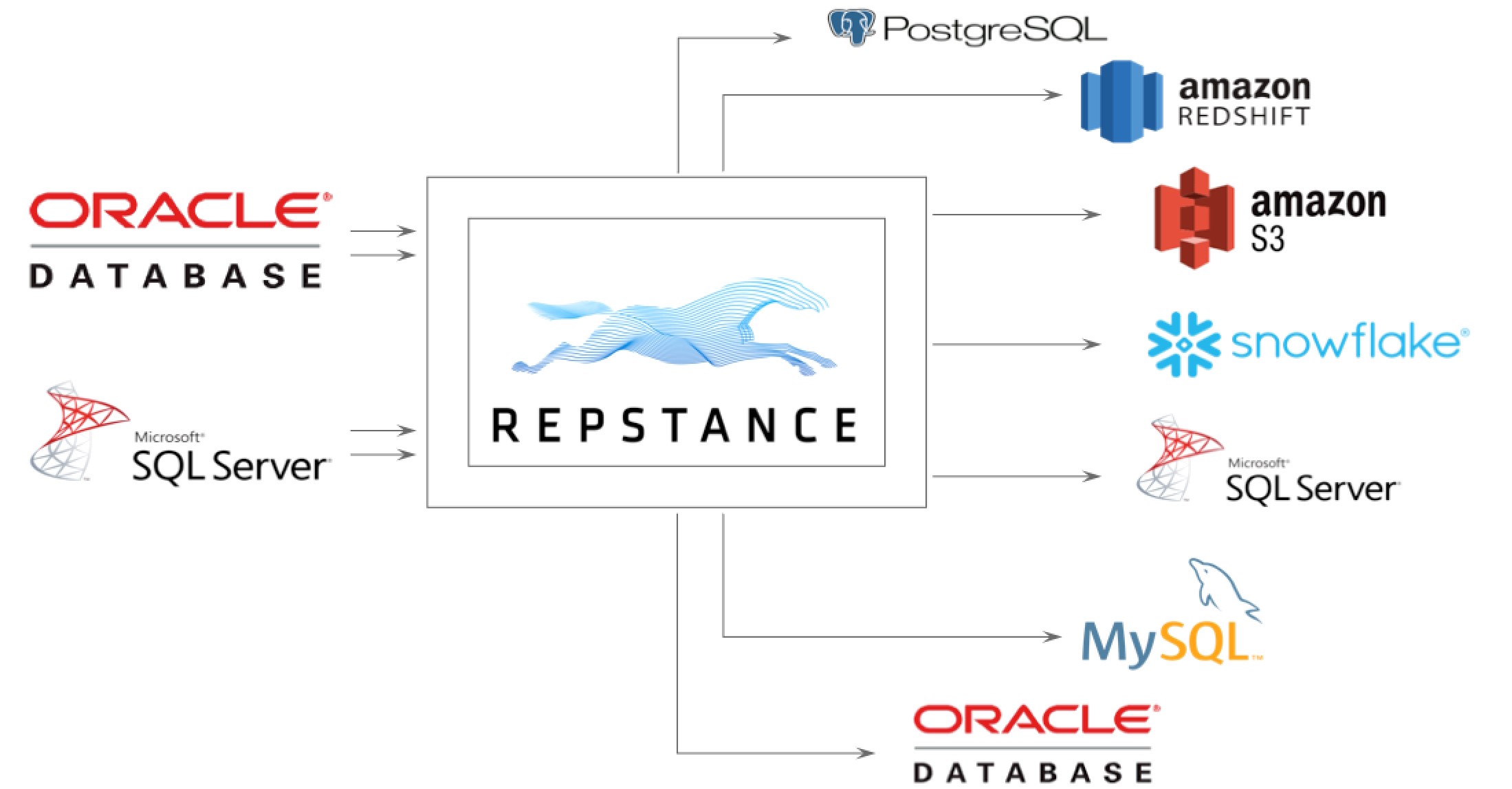
Repstance Architecture Overview
Repstance functions as Linux service. It requires access to both Source and Target Databases, in addition it needs a set of minimal Database Objects to function. To replicate data Repstance uses Capture and Apply Processes. The Capture Process extracts data from the Source Database and puts it into locally stored Trail Files in the same sequential order as the transactions occurred in the database. The Trail Files are consumed by Apply Process to insert the captured data into the Target Database. The Apply Process can also filter and modify data or/and data definition if the appropriate transformation and filtering rules are configured:
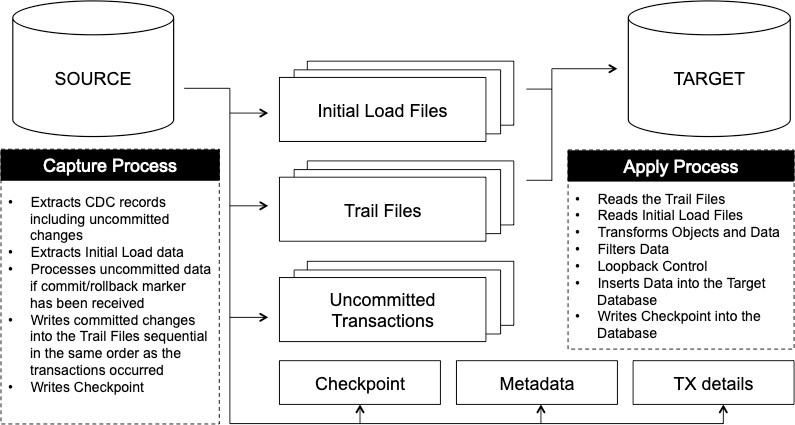
Both of the Processes, while they depend on each other to supply or insert the necessary data they, nonetheless, run as independent threads. The Capture Process does not need to have a running or configured Apply Process as it will quite simply continue extracting data using the criteria supplied, conversely the Apply Process only needs valid Trail Files from a Capture Process to consume.
Prev page:
Repstance User GuideNext page:
SUPPORTED DATABASE REQUIREMENTS- Repstance User Guide
- SUPPORTED DATABASE REQUIREMENTS
- GETTING STARTED WITH REPSTANCE
- INTERACTING WITH REPSTANCE SERVER
- CONFIGURE REPLICATION WITH REPSTANCE
- DATABASE CONFIGURATION COMMANDS
- PROCESS CONFIGURATION COMMANDS
- PROCESS CONTROL COMMANDS
- DATA COMPARISON
- REPSTANCE WEB USER INTERFACE
- REPSTANCE SERVER MAINTENANCE
- GLOSSARY